
Azure IO Testing
One of the first things we do here at VLDB when we have a yearning to set up a database on a cloud platform is to develop an understanding of disk input-output (IO) performance.

For databases in particular, we are specifically interested in random read performance. A high random read throughput figure is necessary for an efficient and performant MPP database.
Microsoft’s Azure is the test platform in question. The approach taken is to commission a single CentOS7 VM, attach various disks and measure IOPS & throughput.
Azure VM Setup
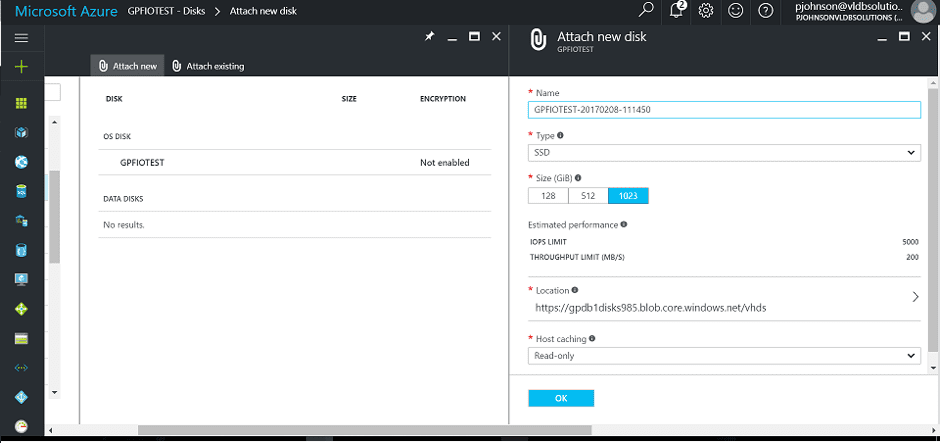
Azure Disk Console
A single Centos 7 VM is configured. Disks are added in he required size, type & number in order to maximise IO throughput at the VM level:The starting point on Azure is SSD disks, as the IO figures for SSD are generally superior to HDD.
Disk size determines both throughput and available IOPS, so this will also need to be considered in the overall build:
Azure VM & Disk Choices
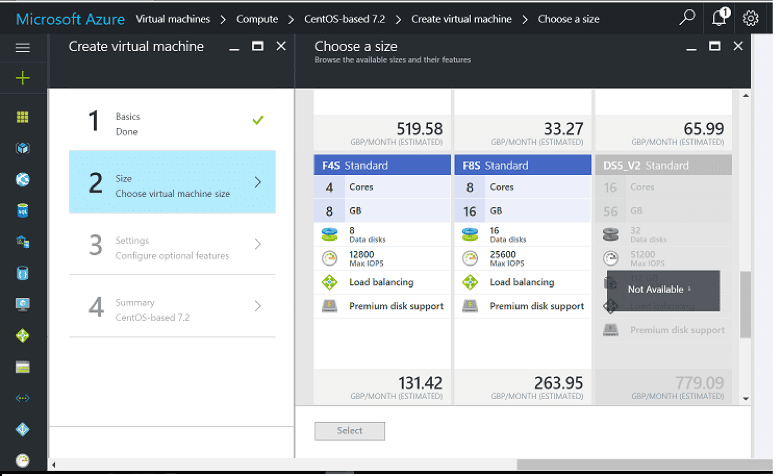
Azure UK Console
For the 1TB SSD selected above, IOPS are limited to 5,000/sec and throughput is limited to 200 MB/s.
As an aside, cloud providers usually fail to distinguish between read & write, sequential & random or specify IO size when they bandy about throughput figures. The devil is in the detail, dear reader(s).

Azure ds14v2
In order to use premium storage it is necessary to specify the account as ‘Premium LRS’.The range available that is hosted in the UK is limited so if you have a requirement for UK based system, make sure that what is on offer from Azure will satisfy the requirement: Note that only certain VM types support SSD disks.
For the basic D14v2 with 16 CPU cores, 112Gb RAM and 800 Gb disk, it is not possible to specify SSD disks. However, the Ds14V2 VM type will allow these ‘Premium’ disks.

Azure P30
Also note that the 800GB is for the operating system and swap space only – the storage is non-persistent on this device specifically.The D14 also allows up to 8 NICs and has an ‘extremely high’ network bandwidth. This is useful if the requirements is to build a MPP cluster to facilitate high speed node:node data transfer.
The Ds14V2 VM is limited to 32 disks:The Standard_DS14_v2 VM is limited to 64K IOPS or 512MB/s in cached mode (host cache = read or read/write) or 51K IOPS (768MB/s) in uncached mode (host cache = none).The P30 1Tb SSD disks used are rated at 5K IOPS (200Mb/s) max per disk:
Azure IOPS Testing
Booting CentOS7 and upgrading the kernel takes a matter of minutes.FIO is then downloaded using git and installed to perform the IOPS tests:
git clone –branch fio-2.1.8 http://git.kernel.dk/fio.git /fio
To run a FIO throughput test, simply enter following from the fio directory:
./fio –rw=randread –name=<directory>/fio –size=<size>g –bs=32k –direct=1 –iodepth=16 –ioengine=libaio –time_based -–runtime=<elapse> –group_reporting
-
<directory> – the directory (disk) where the tests are executed.
-
<size> – size of the test file created in GB.
-
<elapse> – elapse time for the test.
-
bs=32k – blocksize (default 4k). 32Kb is a good size to test for database suitability.
-
direct=1 – non-buffered IO.
-
iodepth=16 – concurrent IO threads.
-
ioengine=libaio – native Linux asynchronous IO.
-
time_based – test elapse time.
-
group_reporting – report on group total not individual jobs.
For example:./fio –rw=randread –name=/tests/disk1/fio –size=1g –bs=32k –direct=1 –iodepth=16 –ioengine=libaio –time_based –runtime=30 –group_reporting
Azure Disk Read Results
Multiple random & sequential read tests were executed against a Standard_DS14_v2 VM with between 1-6 SSD disks of P30 1TB SSD per disk. Blocksize is 32Kb in all cases.

Azure IOPS Results
As stated earlier, we are primarily, but not exclusively, interested in read and not write performance when assessing a cloud platform. This is due to the fact that 80-90% of all data warehouse IO activity is read, and only 10-20% is write. If the read performance isn’t good enough we don’t really care about write performance as the platform is probably unsuitable.
Sequential and random read results using fio on Azure are as follows:
Azure Read Performance Observations
Random and sequential read give similar performance. This is both unusual and most welcome for those of us that rely on random read performance for data warehouse systems!
At the VM level, total disk throughput does not increase as more disks are added to the VM. Disk throughput is limited by the VM type and/or user account type. Adding more disks to the VM is not a way to deliver more IOPS. Approximately 540-570MB/s random read throughput with a 32KB blocksize was achieved fairly consistently for between 1-6 P30 1TB SSDs attached to a Standard_DS14_v2 VM.This is slightly higher than the stated 512 MB/s limit for a Standard_DS14_v2 VM, and represents a very good random read throughput figure for a single disk. However, it is disappointing that this figure can’t be increased nearer to 1,000MB/s (which is attainable on AWS) through the use of more than 1 disk per VM.


